Ve světě škrtů a úspor se obtížně hledají prostředky pro rozvojové projekty, jakým je například implementace Business Intelligence řešení – česky podnikového zpravodajství
nebo zkratkou BI
.
O jeho přínosech bylo popsáno mnoho stran papíru, publikována celá řada statí v internetových periodikách či občasnících. My se budeme soustředit na to, jak cíle podnikového zpravodajství – správná data ve správný okamžik ve správné formě – získat v co nejkratším implementačním čase, tedy i za co nejmenší cenu. Půjdeme na to cestou zjednodušování řešení. Vždy je něco za něco, nemáme zázračnou pilulku na hubnutí ani na rapidní snížení ceny implementace.
Obrázkem si ve zkratce připomeneme, jak takové kompletní řešení podnikového zpravodajství může vypadat. Na levé straně máme zdroje dat – ať již nějaký primární ERP systém, nebo plány prodeje v Excelu, a vše v nějakém konsolidovaném stavu potřebujeme analyzovat na straně pravé v klientských nástrojích – ať již v kontingenční tabulce, sestavách nebo pomocí nástroje PowerView.
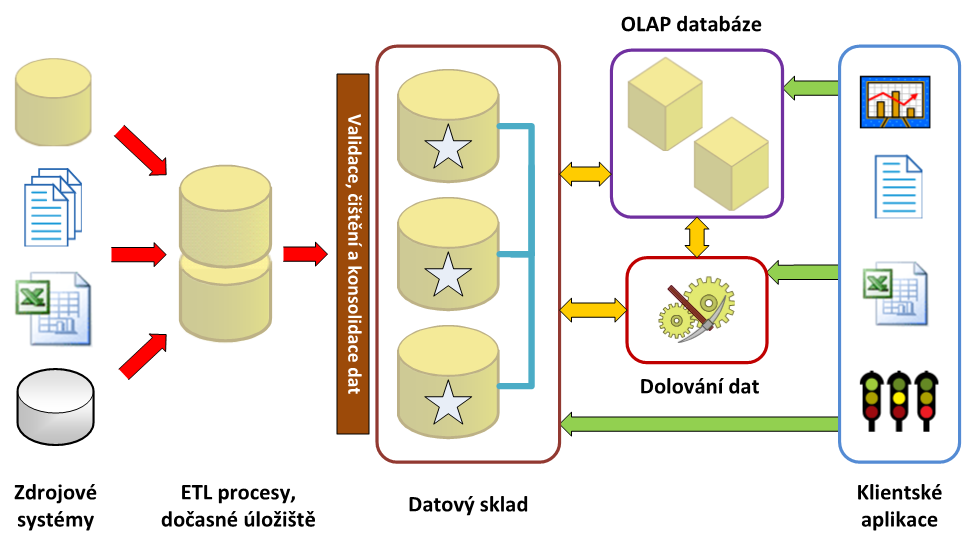
Musíme se tedy zabývat celou vrstvou uprostřed, kterou si v zásadě můžeme rozdělit směrem zleva doprava na části
- zabývající se získáním dat ze zdrojových systémů a jejich uložením do dočasného úložiště
- procesy konsolidace a validace dat
- transformace a uložení dat do datového skladu
- analytická vrstva umožňující vlastní jednoduchou analýzu dat
Nabízí se tedy nápad – co kdybychom vynechali celou vrstvu a připojili klientské nástroje rovnou na primární zdroj dat? Zde, obávám se, můžeme jen těžko hovořit o podnikovém zpravodajství. Vynecháním analytické vrstvy přicházíme o centrální mozek lidstva. Právě analytická vrstva zpřístupňuje data směrem k uživatelům a zařizuje funkčnost jednoho ze šamanských zaklínadel podnikového zpravodajství – jednu verzi pravdy.
Co to ale znamená v praxi? Všechny naše sestavy i analýzy vycházejí z jednoho zdroje dat, který kromě snadnosti přístupu v sobě zahrnuje veškeré možné vzorce pro různé druhy výpočtů. Výpočty jsou v modelu zavedeny buď v podobě vypočítaných měřítek (kalkulací) nebo také v podobě klíčových ukazatelů výkonnosti (KPI).
Analytické vrstvy se tedy zbavit nemůžeme. Nezbývá nám nic jiného než chirurgicky odstranit datový sklad. Chirurgicky se dá odstranit kde co – například i noha, ale otázkou zůstává, jestli, byť citlivě vedený, řez do našeho řešení nezpůsobí více škody než užitku.
Datový sklad a procesy pro získávání a transformaci plní několik klíčových úloh – když tyto vlastnosti dokážeme obětovat a jejich neexistence nebude limitujícím faktorem, skutečně dokážeme výrazným způsobem zkrátit dobu implementace řešení, a tím pádem rapidně snížit i cenu. Abychom se mohli rozhodnout, musíme vědět, které že ty unikátní vlastnosti jsou.
Historizace a sbírání snímků
Ze zdrojového systému bývá někdy obtížné, jindy nemožné získat informaci, jaký byl stav atributu (sloupce) dimenze (tabulky) v minulosti. Např. může být velmi komplikované zjistit rozpracovanosti obchodních příležitostí minulý rok v červnu, případně i jakou měl adresu zákazník před třemi lety, než se přestěhoval. Z hlediska analýzy však tato historizace má zásadní význam. Nemůžeme vzít historické prodeje zákazníka v jiném městě a přestěhovat je i s ním do aktuálního. Procesy pro plnění datového skladu se právě o toto sbírání a archivaci historických snímků dat starají. Díky nim vznikají v datovém skladu unikátní data, která mnohdy nelze žádným způsobem zpětně získat z primárních systémů.
Čistota a konsolidace dat
Při použití datového skladu můžeme využít celou řadu technik ke slučování dat z více různých zdrojů. Nacházíme-li se v situaci, že máme více systémů a v každém z nich obhospodařujeme kmen zákazníků jiným způsobem – např. v CRM systému máme zákazníka Bivoj, s.r.o. s adresou Náměstí 28. dubna a ve fakturačním systému zákazníka Bivoj, sro s adresou nám. 28. Dubna a mezi zákazníky neexistuje jednoznačné propojení – datový sklad nám dokáže pomoci. Procesy, které jej plní, mohou implementovat slučovací logiku od té jednoduché (sloučení přes IČO) až k mnohem komplikovanější, neboť pod jedním IČO mohou vystupovat i různí zákazníci (pobočky, které chceme sloučit do hierarchie atp.).
Velmi snadno se také může stát, že máme ve svém systému zákazníka zavedeného více než jednou. Pokud takovou duplicitu nalezneme a primární systém to umožňuje, můžeme je sloučit do jednoho. Ovšem můžeme narazit na různé důvody, ať již procesní, nebo systémové, kdy nebudeme takto vzniklé duplicitní zákazníky na straně primárního systému schopni sloučit. Zde opět nastupují procesy plnění datového skladu, které se o tento problém dokáží postarat a vyřešit jej ke spokojenosti analytika.
Ke zkvalitnění dat vede nejen jejich deduplikace a konsolidace, ale i další procesy a vnitřní struktura datového skladu. Procesy plnění například zajistí, že všechny neidentifikovatelné nebo špatně identifikované řádky se přiřadí k atributu Nezadáno. Např. nelze-li jednoznačně identifikovat účet transakce, je zadáno špatné datum (mimo rozsah) atd. V analytické vrstvě lze potom tato „záhadná“ čísla snadno identifikovat a zpětně zjednat nápravu ve zdrojovém systému.
Analytická část
Dokážeme-li krvavou řež v podobě obětování jednotlivých funkcionalit datového skladu přežít, nabízí se nám využití nové analytické platformy ze stáje Microsoftu – modelu tabular, někdy také xVelocity nebo PowerPivot. Všechny názvy v sobě zahrnují stejnou technologii a velmi podobné nástroje i stejné modelovací techniky. Nástroje jsou to relativně jednoduché na využití, ale sada funkcionalit je ve verzi SQL Serveru téměř shodná s plnohodnotnými BI nástroji.
O co se tedy jedná? Ve stručnosti lze říct, že máme k dispozici tvůrce kontingenční tabulky na druhou. Celý model si můžeme představit jako velkou plochou strukturu (jednu tabulku), která obsahuje veškeré sloupce, které do ní vložíme (i z různých jiných tabulek pomocí vztahů). Veškeré výpočty jsou realizovány pomocí vzorců velmi podobných těm v Excelu a model můžeme obohatit i o takové příjemnosti, jako jsou hierarchie a klíčové ukazatele výkonu.
Výsledkem je, že jsme skutečně schopni vystavět plnohodnotné BI řešení bez datového skladu, sice s celou řadou omezení, vyplývajících právě z přeskočení celého vývojového stupně (datového skladu), ale přece! Dokonce jsme schopni analytický model postavit na technologiích, které jsou blízké pokročilým uživatelům – v zásadě je to nová, pokročilá verze kontingenční tabulky. A dá se říct, že pro tvorbu malých řešení, případně řešení BI pro jednotlivé oblasti podnikání, se jedná o velmi vhodnou a flexibilní technologii.
I takové cesty umí ukázat BI Experts, společnost zaměřená na konverzi dat v informace. Jeden z Murphyho zákonů (nejen pro IT) říká: Vždycky je potřeba obětovat něco, co chceme, něčemu, co chceme ještě více. Jestli je pro vás klíčovým parametrem rychlost a cena, můžete zvolit cestu nedokonalého, ale přesto funkčního řešení. Třeba prozatím. Ne vždycky se vyplatí „umřít pro krásu“…
Erik Caha | BI Experts
erik.caha@biexperts.cz